語音助理是個可以對你用聲音所下達的指令做出回應的一個工具,現在最紅的大概是Siri(Apple)、Alexa(Amazon)、Google assistance(GOOGLE)、CORTANA(Microsoft),這幾家大廠各自都在自己的產品上使用自家開發的語音助理。
在網路上看到有人對這幾家的語音助理詢問各種問題,並根據回答進行評分。結果似乎大部分都是指出siri是比較笨拙,而google assistance 最聰明!!


語音助理的應用很多,舉凡打電話、導航、設備控制、資訊查詢、語言翻譯、心靈伴侶…等。
實做上基本包括幾個項目:
speech to text、text to intent 、corresponding action、text to speech
至少需要的相關套件為以下幾個,都可以pip install,其他的就看你要寫哪些功能再另外安裝~
import speech_recognition # speech to text
import pyaudio #for麥克風收音
from gtts import gTTS #text to speech via google
from pygame import mixer #說出聲音speech to text (關鍵技術!)
Amazon、google、Microsoft 都有提供此功能之API但基本上要錢的,而Python 的SpeechRecognition 把一些API 給整個打包起來讓我們方便在python中呼叫。其中google speech recognition為免費!(但相較付費版功能較簡易,如無法自動偵測語言、自訂字詞、自動標點符號、說話者分段標記),雖然是免費版,但也是很夠用了,幾乎都沒有錯誤。
一旦你將聲音轉成文字,那接下來的工作就是文字處理,和語音無關了
要如何在python 使用SpeechRecognition 把語音轉成文字呢? 參考大數軟體的教學就可以很簡單的做到,大概就像以下幾個函數:
調用這兩個函數就可以讓python 聽聲音和發出聲音~
Text to intent
要如何讓機器理解文字的意圖並回應這是決定你的助理有多聰明的關鍵,可以使用高超的NLP技術來理解,也可以用超大量的if-else來造出假AI。
而我是使用介於兩著之間自己亂搞的方法XD,若以後有緣學了些NLP技術再來改進吧~
我的作法概念是:
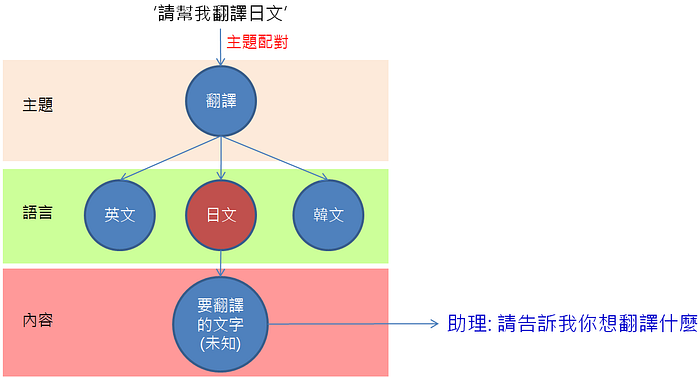
設定幾個主題(e.g.問時間、天氣、翻譯、查詢…等),而每個主題有幾個關鍵字,若下命令的語句有打中關鍵字,則直接判斷使用者是想使用該主題的功能(if-else base)而若下的命令沒有打中關鍵字則先斷詞,然後使用 word2vec 計算命令中的詞和哪個主題的關鍵字最相近(簡易NLP)。
而每個主題設定幾個必要的資訊,如 '翻譯' 小助理會需要知道想翻譯什麼語言以及想翻譯的文字,若下命令的語句中有缺乏的資訊,則使用多輪對話來取得。
接著稍微說一下 word2vec:
word2vec 是個將文字單詞轉換成向量的技術(word embedding),屬於一種unsupervised learning的model。
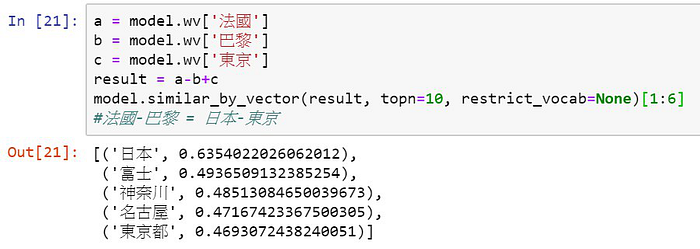
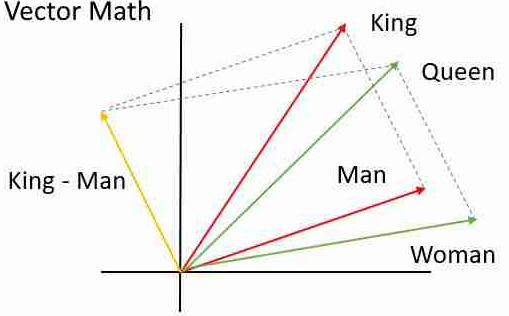
字辭意義相近的字在投射過去的高維空間中會有較接近的cosine distance,且可以在這空間進行運算,如 法國 - 巴黎 + 東京 = 日本,也就是法國之餘巴黎相當於日本之餘東京
word2vec 是由Tomas Mikolov 在 google 團隊中發表的 Efficient Estimation of Word Representations in Vector Space 開始出現的
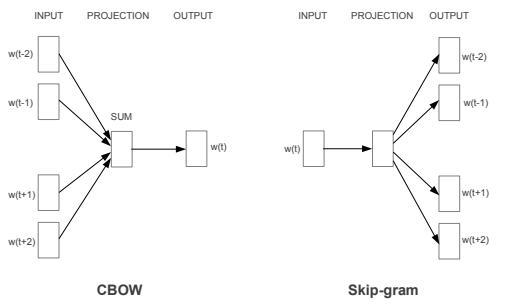
主要有兩種 model: Continuous Bag-of-Words(CBOW) 和 Skip-gram,分別是由上下文預測中間的字以及由中間的字預測上下文,如下圖:
可以看到都是只有一層hidden layer的neural network,然後接 softmax output。對於word2vec 來說,訓練這兩種模型可以算是一個fake task,我們最終想要的word vector 是這個模型中間的hidden layer。
因為文字沒辦法當作neural network的input 所以首先要先有辭典,每個詞都以one-hot vector來表示(假設辭典有10000個詞,那每個詞都是10000維度的one-hot vector)
假設我們的文本是 ”The quick brown fox jumps over the lazy dog”,然後設定window size=2 (上下文看的範圍) 那麼:
- 以CBOW來說,若當下的字是’fox’ 那麼 input 為quick、brown、jumps、over的one-hot 向量,4個向量經過運算後取平均得到一個hidden layer(如下圖),而output 為fox 的one-hot。
- 而skip-gram而言fox 這個字就會有(fox,quick),(fox,brown),(fox,jumps),(fox,over) 這幾個樣本,每個input都是 fox,而output 各自為quick,brown,jumps,over的one-hot 然後計算cross-entropy 來回饋。


可想而知,這個網路是一個前後超胖的淺層網路,假設我們字典有10,000個字,中間hidden layer dimension為300,那麼就會有
10,000*300+300*10,000個權重,且因為是one-hot encoder,會有一大堆的0 所以若使用一般NN的 framework 就太浪費了!
因此在計算的時候可以有些小技巧:
- 做矩陣運算時,我們只需要對 one-hot的index 在權重矩陣裡取值就可以,不用真的計算内積(如下圖)

2. 使用hierarchical softmax 或 negative sampling 來降低運算量,同時降低noise的影響:
我個人覺得negative sampling 比較直觀好理解。negative sampling 是指每次訓練時只update部分的權重。比如剛剛的例子 input ‘fox’ output ‘jumps’來update網路時,我們期望jumps的位置為1,而jumps外的9999個字為0,
這9999個就是negative words,negative sampling 就是從negative words裡抽樣一小部分的字並只 update這幾個字相關的權重,大幅降低每次更新神經元的數量,同時也有種dropout的感覺使模型更robust。
實際在 python實作是以 gensim來實踐,如何訓練model可以參考這篇。
我是跟著這篇文章以wiki的文本資料庫來訓練CBOW model,約34萬篇文章,7808萬個字詞。
當訓練完後,就可以像以下這樣調用model計算單詞間的相似度~
corresponding action
這一部分就看你自己想寫哪些功能,舉幾個我寫的例子(翻譯、天氣、時間)
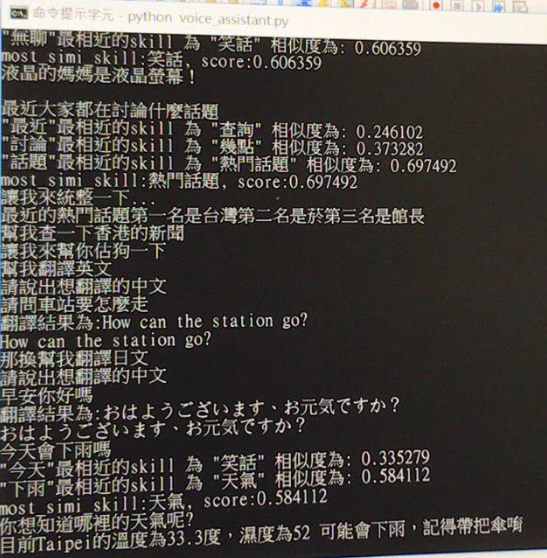
幾輪對話的結果:
心得
其實整個做下來,就是透過API 語音轉文字、文字轉語音,中間再自己亂玩,雖然沒什麼高深的技術,但自己跟程式對話會很有AI的感覺,還蠻好玩的 哈哈。
接著就是想做什麼功能就加在小助理的技能裡就能一直擴張,只是主題配對的技術可能可以在研究一下。
